
# 字节序
即计算机在存储或读取数据时,字节的顺序。计算机是从低字节依次向高字节进行 读。 数据
12345678
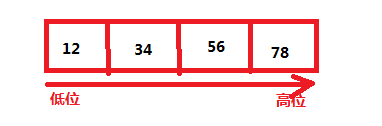
- 大端:
低字节在高位(即后面),高字节在前面(符合人类的习惯)
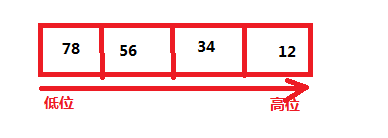
- 小端:
低字节在低位(即前面)
计算机一般都是小端序
网络序时大端序
#include <stdio.h> | |
union | |
{ | |
short a; | |
char b[2]; | |
} un; | |
int main(void) | |
{ | |
un.a = 0x1234; //0x 十六进制,0 八进制 | |
if (un.b[0] == 0x34) // 低字节存放在低位,小端 | |
{ | |
printf("小端序"); | |
} | |
else if(un.b[0] == 0x12) // 高字节存在低位,低字节存在高位, | |
{ | |
printf("大端序"); | |
} | |
return 0; | |
} |
# 常见的处理器架构
| 架构 | 模式 | 描述 |
|---|---|---|
x86/x64 | 小端 模式 | |
ARM | 大小端模式 可配置 | 1 为 大 端, 0 为 小 端, 复位时 确认,不能更改 |
# 为什么要区分大小端
芯片存储空间以字节为
单位存储,每个字节都有高低地址之分,只有超过了一个字节的数据,就需要区分呢大端还是小端。
大小端的优缺点来说。存储效率,在 CPU 计算时内核效率。
# 大端小端优缺点对比
# 数据传输
- 网络传输使用大端字节序可以
避免字节序转换带来的性能损失。传输中,若需要进行字节序转换,会增加CPU的工作负载,降低系统性能。网络数据包都是先传输头部信息,然后再传输数据,采用大端字节序可以使头部信息的数据大小和起始位置固定,方便处理。
# 数据存储
- 容易
判断多字节数据的大小 - 提高
内存利用率
小端存储地地址 总是存放着
数据最低的有效字节,而高地址存放着数据的最高有效字节,这些特征使得小端序列的地址按值递增时,多字节数据的存储顺序和阅读顺序都是按顺序排列的,可以充分利用内存的特征。大端序列却不好 利用内存。如下:

小端字节序,低位字节总是存储在最低的地,对于多字节整数的部分访问和计算更加方便
# Linux 对字节序转换
将
长整型转换为网络大端字节序,使用htonl,短整型使用htons将
网络字节序转换为本地小端字节序,使用ntohl,短整型使用ntohs()
The htonl() function converts the unsigned integer hostlong from host byte order to network byte order. | |
The htons() function converts the unsigned short integer hostshort from host byte order to network byte order. | |
The ntohl() function converts the unsigned integer netlong from network byte order to host byte order. | |
The ntohs() function converts the unsigned short integer netshort from network byte order to host byte order. |